Bigquery中sql语句常用命令
连接数据库
gcloud sql connect qwiklabs-demo --user=root
合并两个表格union
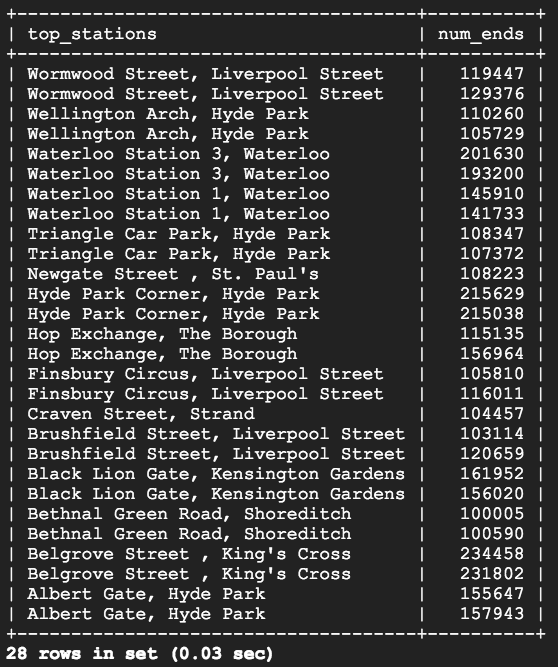
SELECT start_station_name AS top_stations, num FROM london1 WHERE num>100000
UNION
SELECT end_station_name, num FROM london2 WHERE num>100000
ORDER BY top_stations DESC;
UNION中间的关键字通过将“ london2”数据与“ london1”同化来组合这些查询的输出。由于将“ london1”与“ london2”结合在一起,因此列名优先为“ top_stations”和“ num”。
ORDER BY 将按照“ top_stations”列值的字母顺序和降序对最终的联合表进行排序。
添加数据 insert into 表 (字段,字段) values (值,值);
INSERT INTO london1 (start_station_name, num) VALUES ("test destination", 1);
运行查询命令
bq query --use_legacy_sql=false 'select 字段 from 表格 where 条件' 注意的地方是
use_legacy_sql=false 表示使用标准sql语句
条件的时候可以使用双引号做区分""
#standardSQL
SELECT FROM `data-to-inghts.ecommerce.rev_transactions` LIMIT 1000
What's wrong with the previous query to view 1000 items? check
There is a typo in the dataset name check
We have not specified any columns in the SELECT
There is a typo in the table name
We are using legacy SQL
what about this updated query?
#standardSQL
SELECT * FROM [data-to-insights:ecommerce.rev_transactions] LIMIT 1000
'''
we are using legacy sql
what about this query that uses standard SQL
```sql
#standardSQL
SELECT FROM `data-to-insights.ecommerce.rev_transactions`
no columns defined in select
what about now?
#standardSQL
SELECT
fullVisitorId
FROM `data-to-insights.ecommerce.rev_transactions`
without aggregations,limits or sorting, this query is not insightful
what about now?
#standardSQL
SELECT fullVisitorId hits_page_pageTitle
FROM `data-to-insights.ecommerce.rev_transactions` LIMIT 1000
it can be excuated.
what about now?
#standardSQL
SELECT
fullVisitorId
, hits_page_pageTitle
FROM `data-to-insights.ecommerce.rev_transactions` LIMIT 1000
this returns result, but visitors maybe counted twice.
what about this? an aggregation function, count(), was added.
#standardSQL
SELECT
COUNT(fullVisitorId) AS visitor_count
, hits_page_pageTitle
FROM `data-to-insights.ecommerce.rev_transactions`
没去重,the count()function does not de-deduplicate the same fullvisitorid it is missing a group by clause
in this next query, group by and distinct statements were added
#standardSQL
SELECT
COUNT(DISTINCT fullVisitorId) AS visitor_count
, hits_page_pageTitle
FROM `data-to-insights.ecommerce.rev_transactions`
GROUP BY hits_page_pageTitle
we can add filter 'where' to filter results
#standardSQL
SELECT
COUNT(DISTINCT fullVisitorId) AS visitor_count
, hits_page_pageTitle
FROM `data-to-insights.ecommerce.rev_transactions`
WHERE hits_page_pageTitle = "Checkout Confirmation"
GROUP BY hits_page_pageTitle
List the cities with the most transactions with your ecommerce site
SELECT
geoNetwork_city,
sum(totals_transactions) as totals_transactions,
COUNT( DISTINCT fullVisitorId) AS distinct_visitors
FROM
`data-to-insights.ecommerce.rev_transactions`
GROUP BY geoNetwork_city
Order by distinct_visitors Desc
whats wrong with the following query?
#standardSQL
SELECT
geoNetwork_city,
SUM(totals_transactions) AS total_products_ordered,
COUNT( DISTINCT fullVisitorId) AS distinct_visitors,
SUM(totals_transactions) / COUNT( DISTINCT fullVisitorId) AS avg_products_ordered
FROM
`data-to-insights.ecommerce.rev_transactions`
WHERE avg_products_ordered > 20
GROUP BY geoNetwork_city
ORDER BY avg_products_ordered DESC
we cannot filter aggregated fields in the 'where' clause ( use 'Having' instead) 不可以用where来聚合函数的字段,要用having we cannot filter on aliased fields within the 'where' clause where过滤句中不能使用别名
possible solution
select geoNetwork_city, SUM(totals_transactions) as total_products_ordered, count(distinct fullvisitorID) as distinct_visitors,
sum(totals_transactions) / count(distinct fullVisitorId) As avg_products_ordered
from
`data-to-insights.ecommerce.rev_transactions`
Group by geoNetwork_city
Having avg_products_ordered > 20
order by avg_products_ordered
#standardSQL
SELECT
COUNT(hits_product_v2ProductName) as number_of_products,
hits_product_v2ProductCategory
FROM `data-to-insights.ecommerce.rev_transactions`
WHERE hits_product_v2ProductName IS NOT NULL
GROUP BY hits_product_v2ProductCategory
ORDER BY number_of_products DESC
这里的问题是count()函数里面的字段没有做distinct,有可能导致重复 The count() function is not the distinct number of products in each category
possible solution
#standardSQL
SELECT
COUNT(DISTINCT hits_product_v2ProductName) as number_of_products,
hits_product_v2ProductCategory
FROM `data-to-insights.ecommerce.rev_transactions`
WHERE hits_product_v2ProductName IS NOT NULL
GROUP BY hits_product_v2ProductCategory
ORDER BY number_of_products DESC
LIMIT 5