机器学习-- 1 训练与损失
官方文档信息 1 训练模式通过有标签样本学习所有权重和偏差的理想值.在监督学习中,机器学习算法通过以下方式构建模型,检查多个样本并尝试找出最大限度减少损失的模型,这个过程就是经验风险最小化
损失是对糟糕预测的惩罚。也就是说,损失是一个数值,表示对于单个样本而言模型预测的准确程度。如果模型的预测完全准确,则损失为零,否则损失会较大。训练模型的目标是从所有样本中找到一组平均损失“较小”的权重和偏差。例如,图 3 左侧显示的是损失较大的模型,右侧显示的是损失较小的模型。关于此图,请注意以下几点:
红色箭头表示损失。
蓝线表示预测
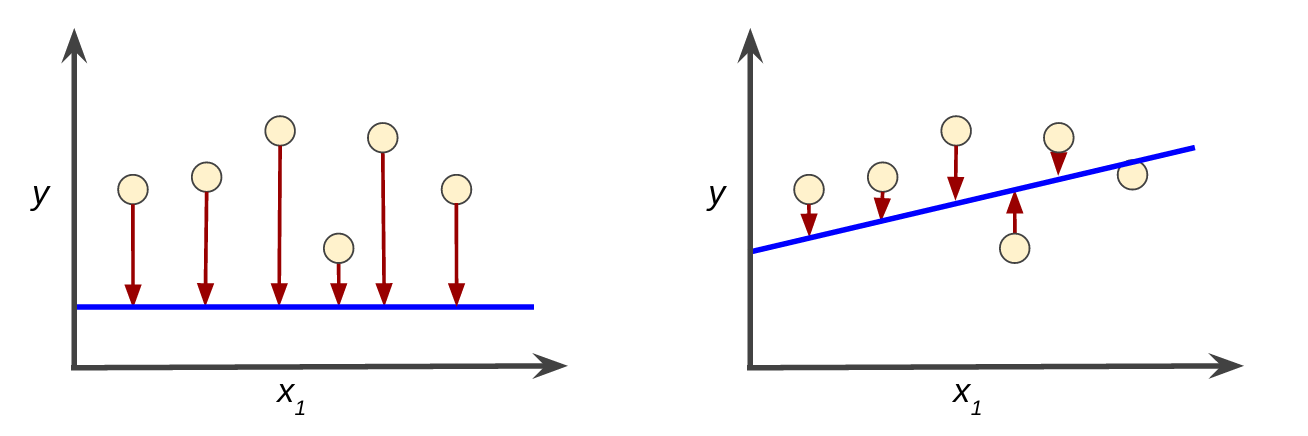
左侧模型的损失较大;右侧模型的损失较小。
平方损失:
= the square of the difference between the label and the prediction
= (observation - prediction(x))2
= (y - y')2
均方误差 (MSE) 指的是每个样本的平均平方损失。要计算 MSE,请求出各个样本的所有平方损失之和,然后除以样本数量:
loss = mean(square(y_true - y_pred), axis=-1)