整个流程是
创建Composer by setting up Composer environment >> create a workflow py file >> 创建Dataproc >> Runs Hadoop job on Dataproc >> deletes Dataproc cluster
step1 Create Enviroment and set up the Enviroment
Name: highcpu
Location: us-central1
Zone: us-central1-a
Machine type: n1-highcpu-4
Python version 3
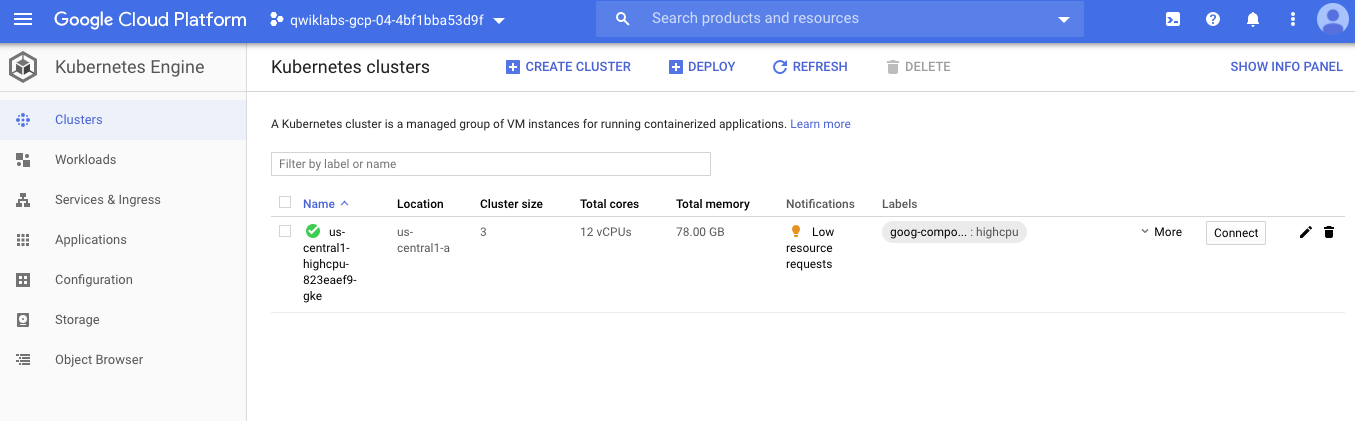
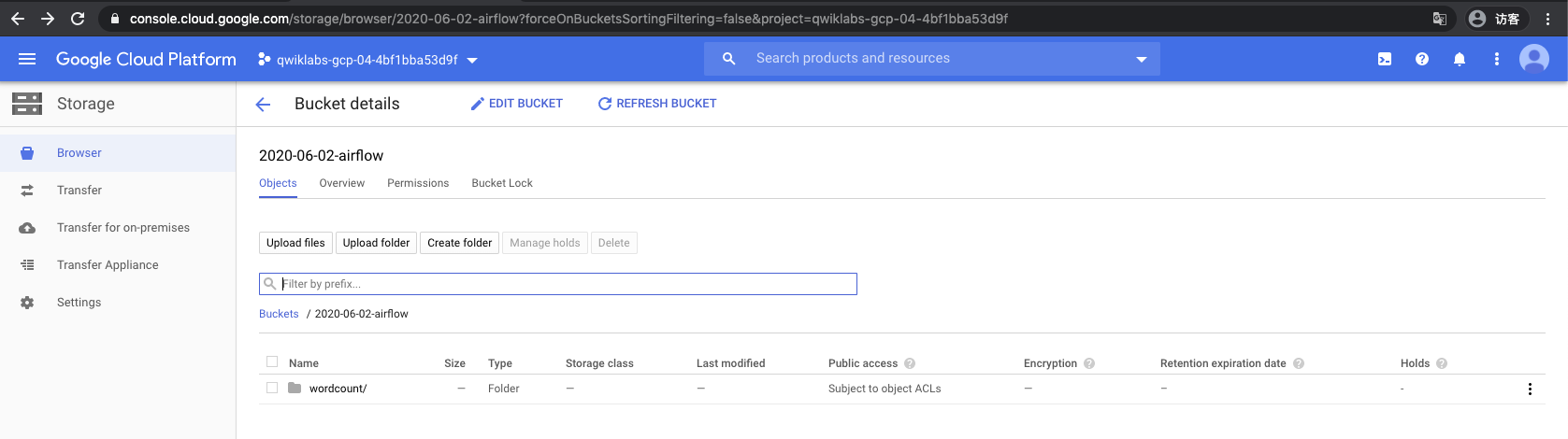
step2 创建GCS bucket
要记住bucket名字, 因为这个是放DAG file的
step3 了解核心概念
Airflow是一个以编程方式编写,安排和监视工作流的平台。 使用Airflow将工作流编写为任务的有向无环图(DAG), 就是单向的
DAG: 有向无环图是您要运行的所有任务的集合,以反映其关系和依赖性的方式进行组织。
Operator: 就是对单一任务的描述
Task: 操作员的参数化实例;DAG中的一个节点
Task Instance: 任务的特定运行;其特征是:DAG,任务和时间点。它具有指示性状态:运行,成功,失败,跳过
step4: 设定一个workflow 工作流
- Composer workflows是由DAGs组成的. DAGs 就是被定义好的标准python文件, 这些文件都是放在Airflow的DAG_FOLDER中.
- Airflow会动态地执行python文件的代码来构建DAGs对象
- 您可以根据需要拥有任意数量的DAG,每个DAG描述任意数量的任务。通常,每个DAG应对应一个逻辑工作流程workflow。
"""Example Airflow DAG that creates a Cloud Dataproc cluster, runs the Hadoop
wordcount example, and deletes the cluster.
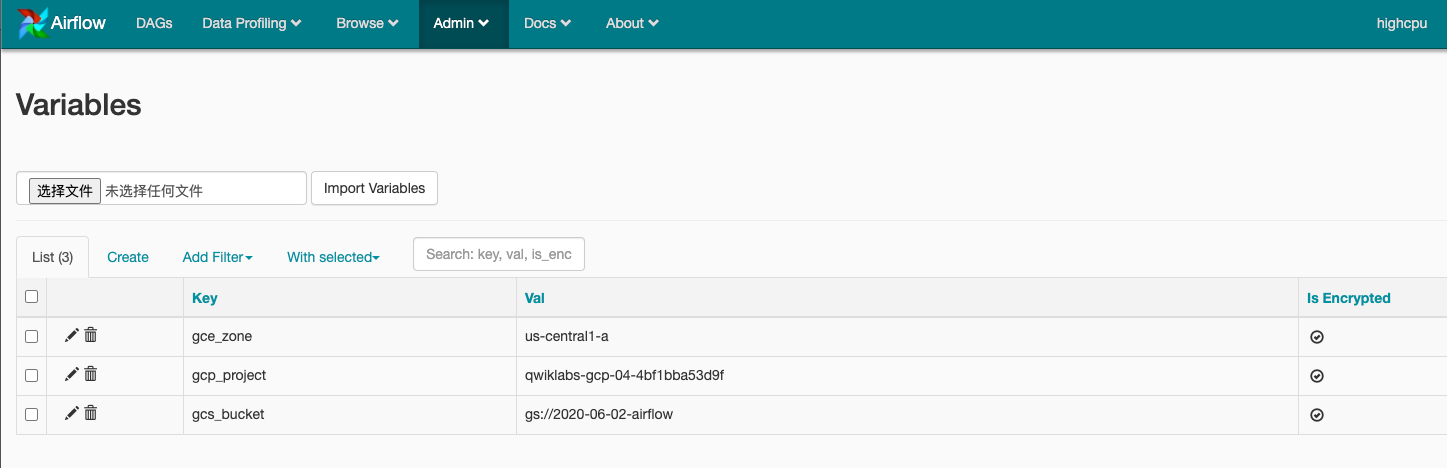
This DAG relies on three Airflow variables
https://airflow.apache.org/concepts.html#variables
这里是在airflow web interface的admin>>varibale设置的
* gcp_project - Google Cloud Project to use for the Cloud Dataproc cluster.
* gce_zone - Google Compute Engine zone where Cloud Dataproc cluster should be
created.
* gcs_bucket - Google Cloud Storage bucket to use for result of Hadoop job.
See https://cloud.google.com/storage/docs/creating-buckets for creating a
bucket.
"""
import datetime
import os
from airflow import models
from airflow.contrib.operators import dataproc_operator
from airflow.utils import trigger_rule
# Output file for Cloud Dataproc job. 输出文件地址
# 输出的地址是通过gcs+文件名字(wordcount) + 时间 + '/'
output_file = os.path.join(
models.Variable.get('gcs_bucket'), 'wordcount',
datetime.datetime.now().strftime('%Y%m%d-%H%M%S')) + os.sep
# Path to Hadoop wordcount example available on every Dataproc cluster.
WORDCOUNT_JAR = (
'file:///usr/lib/hadoop-mapreduce/hadoop-mapreduce-examples.jar'
)
# Arguments to pass to Cloud Dataproc job.
wordcount_args = ['wordcount', 'gs://pub/shakespeare/rose.txt', output_file]
yesterday = datetime.datetime.combine(
datetime.datetime.today() - datetime.timedelta(1),
datetime.datetime.min.time())
default_dag_args = {
# Setting start date as yesterday starts the DAG immediately when it is
# detected in the Cloud Storage bucket.
'start_date': yesterday,
# To email on failure or retry set 'email' arg to your email and enable
# emailing here.
'email_on_failure': False,
'email_on_retry': False,
# If a task fails, retry it once after waiting at least 5 minutes
'retries': 1,
'retry_delay': datetime.timedelta(minutes=5),
'project_id': models.Variable.get('gcp_project')
}
# [START composer_hadoop_schedule]
with models.DAG(
'composer_hadoop_tutorial',
# Continue to run DAG once per day
schedule_interval=datetime.timedelta(days=1),
default_args=default_dag_args) as dag:
# [END composer_hadoop_schedule]
# Create a Cloud Dataproc cluster.
create_dataproc_cluster = dataproc_operator.DataprocClusterCreateOperator(
task_id='create_dataproc_cluster',
# Give the cluster a unique name by appending the date scheduled.
# See https://airflow.apache.org/code.html#default-variables
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
num_workers=2,
zone=models.Variable.get('gce_zone'),
master_machine_type='n1-standard-1',
worker_machine_type='n1-standard-1')
# Run the Hadoop wordcount example installed on the Cloud Dataproc cluster
# master node.
run_dataproc_hadoop = dataproc_operator.DataProcHadoopOperator(
task_id='run_dataproc_hadoop',
main_jar=WORDCOUNT_JAR,
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
arguments=wordcount_args)
# Delete Cloud Dataproc cluster.
delete_dataproc_cluster = dataproc_operator.DataprocClusterDeleteOperator(
task_id='delete_dataproc_cluster',
cluster_name='composer-hadoop-tutorial-cluster-{{ ds_nodash }}',
# Setting trigger_rule to ALL_DONE causes the cluster to be deleted
# even if the Dataproc job fails.
trigger_rule=trigger_rule.TriggerRule.ALL_DONE)
# [START composer_hadoop_steps]
# Define DAG dependencies.
create_dataproc_cluster >> run_dataproc_hadoop >> delete_dataproc_cluster
# [END composer_hadoop_steps]
为了协调这三个工作流程任务,DAG导入了以下运算符:
DataprocClusterCreateOperator:创建一个Cloud Dataproc集群。 DataProcHadoopOperator:提交Hadoop wordcount作业并将结果写入Cloud Storage存储桶。 DataprocClusterDeleteOperator:删除群集以避免产生持续的Compute Engine费用。
任务按顺序运行,您可以在文件的此部分中看到
# Define DAG dependencies.
create_dataproc_cluster >> run_dataproc_hadoop >> delete_dataproc_cluster
DAG的名称为hadoop_tutorial,并且DAG每天运行一次。
with models.DAG(
'composer_hadoop_tutorial',
# Continue to run DAG once per day
schedule_interval=datetime.timedelta(days=1),
default_args=default_dag_args) as dag:
由于start_date传递给default_dag_args的设置为yesterday,因此Cloud Composer安排工作流在DAG上传后立即开始。
step5 设置airflow变量
- 去airflow web interface
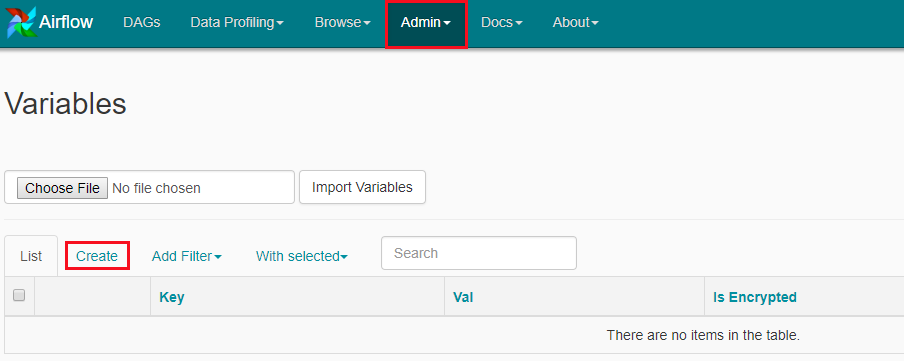
- 创建以下Aireflow变量gcp_project,gcs_bucket以及gce_zone:
step6 将DAG上载到云存储
在Cloud Shell中,将hadoop_tutorial.py复制并保存在本地虚拟机上
git clone https://github.com/GoogleCloudPlatform/python-docs-samples
转到python-docs-samples目录:
cd python-docs-samples/composer/workflows
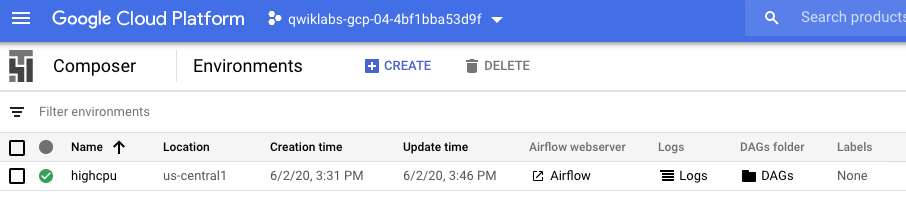
现在,将hadoop_tutorial.py文件的副本上载到Cloud Storage存储桶,该存储桶在创建环境时会自动创建。您可以通过转到Composer > 环境进行检查。单击您先前创建的环境,这将带您进入所创建环境的描述。查找DAGs folder,复制要替换的值,DAGs_folder_path并在以下命令中上传文件:
gsutil cp hadoop_tutorial.py DAGs_folder_path

探索DAG运行 当您将DAG文件上传到dagsCloud Storage中的文件夹时,Cloud Composer会解析该文件。如果未找到错误,则工作流的名称将显示在DAG列表中,并且该工作流已排队等待立即运行。
确保您在Airflow Web界面的DAG选项卡上。此过程需要几分钟才能完成。刷新浏览器以确保您正在查看最新信息。
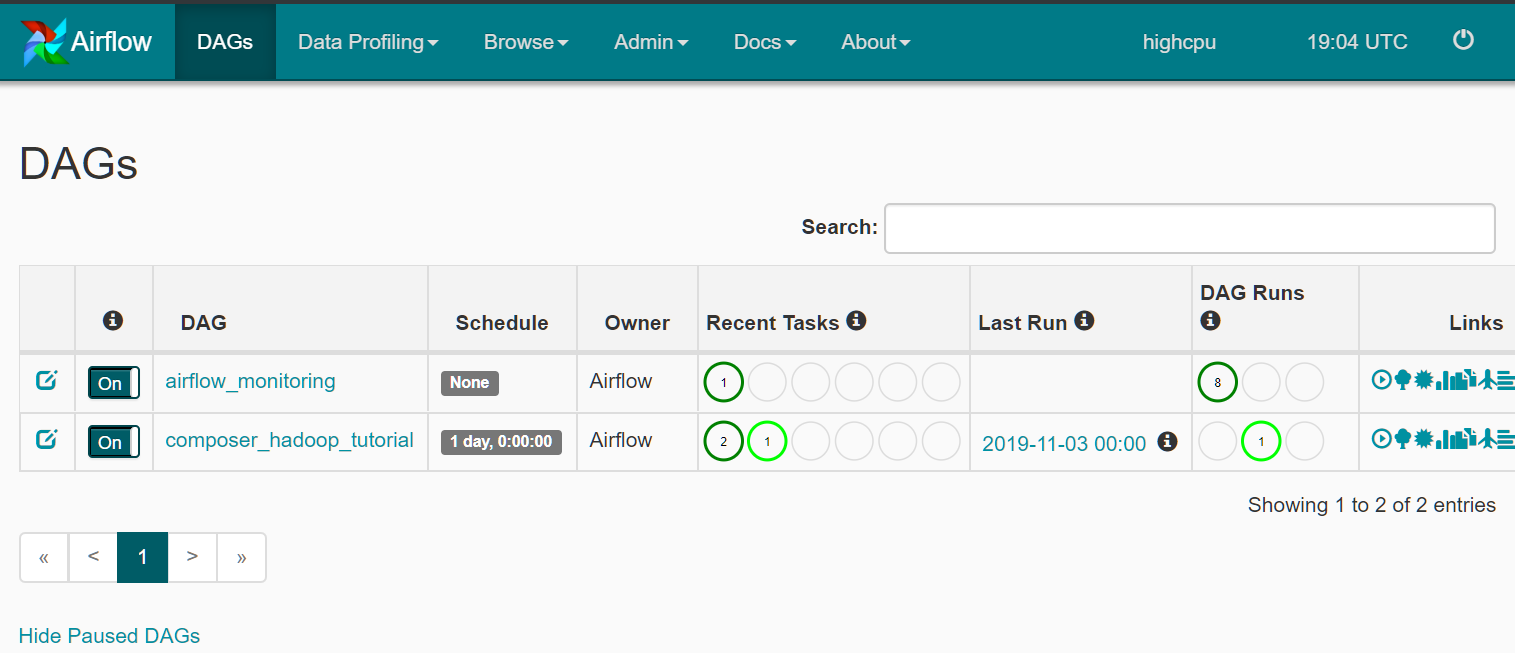
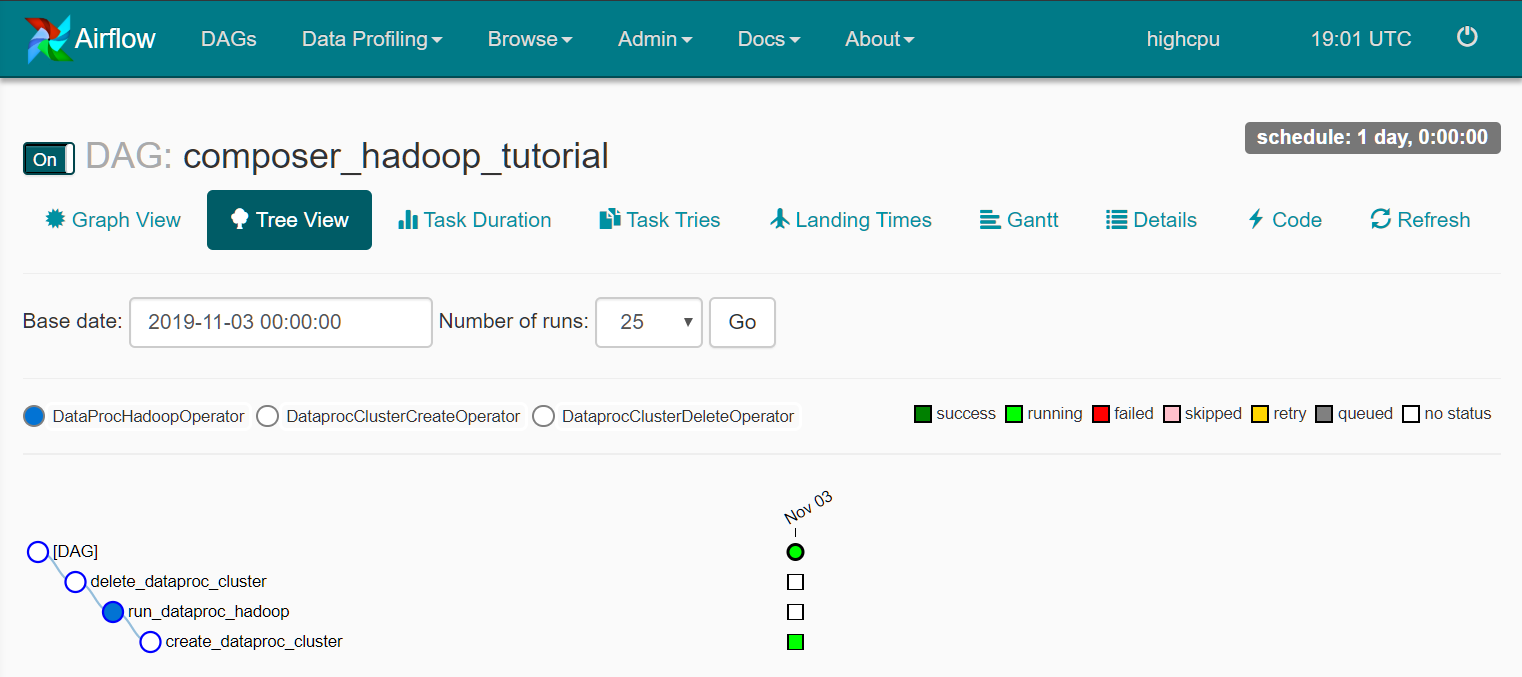
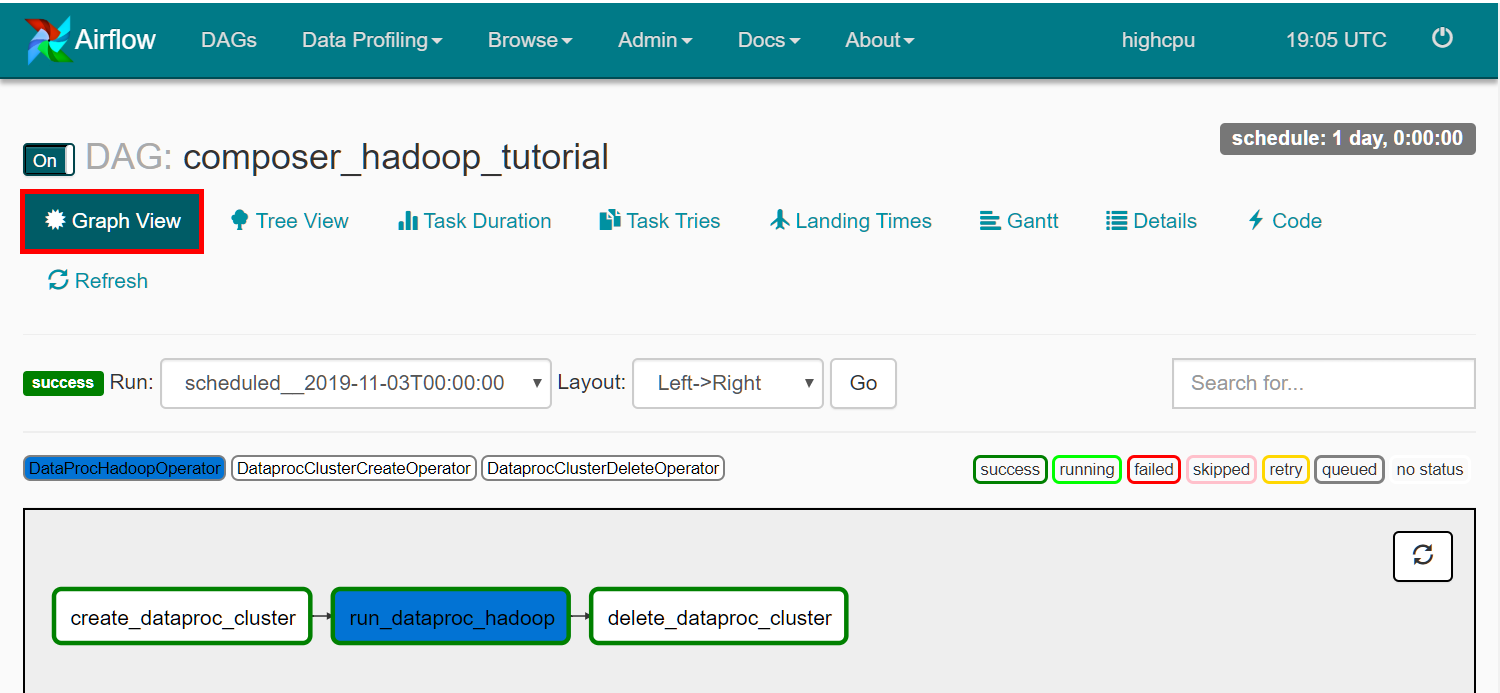
step7 重新运行工作流程
- 单击create_dataproc_cluster图形。
- 单击清除以重置三个任务。
- 然后单击确定进行确认。请注意,create_dataproc_cluster周围的颜色已更改,状态为“正在运行”。
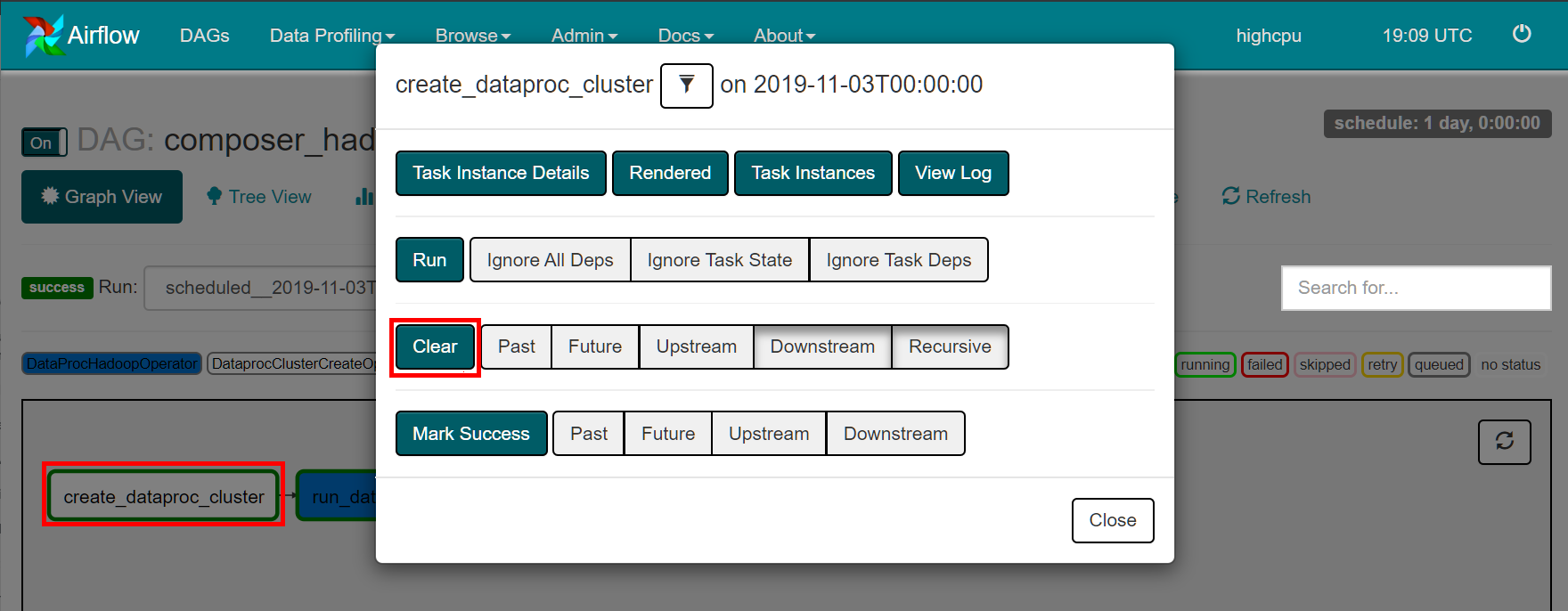
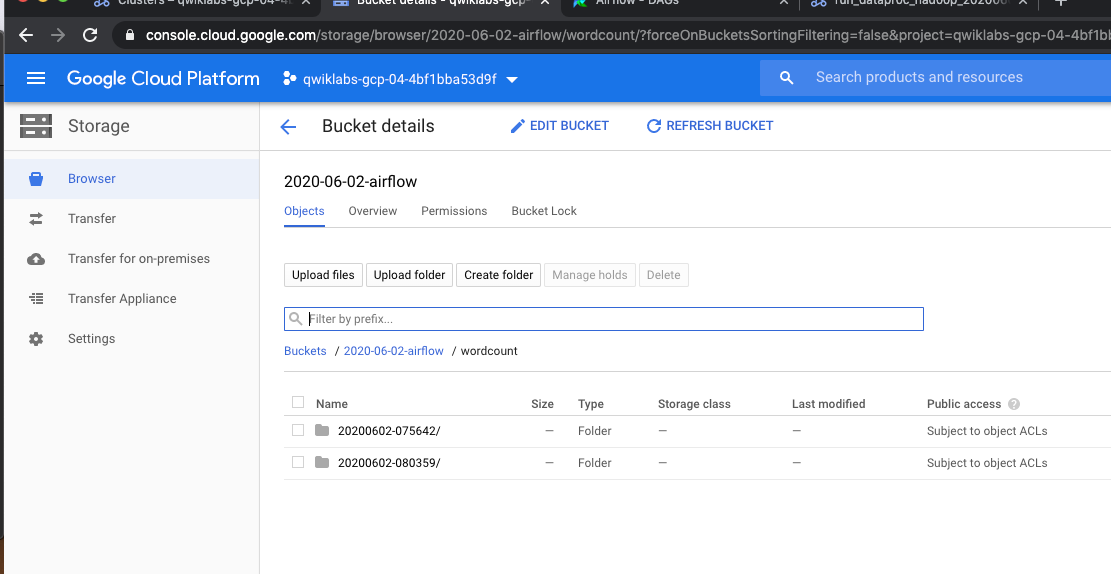
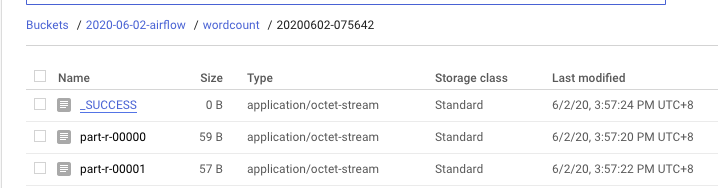
我们可以看到dataproc具体的运行情况
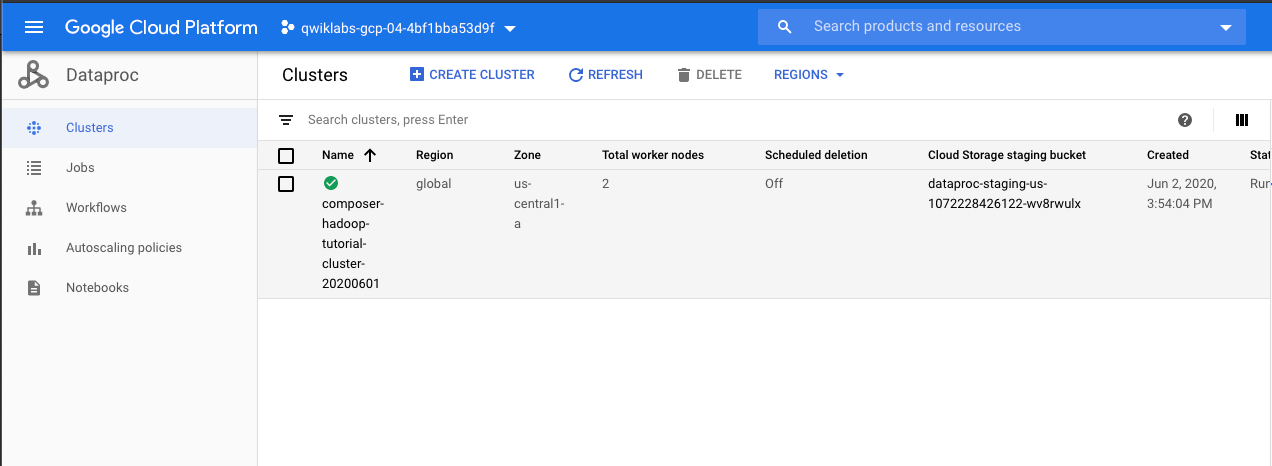
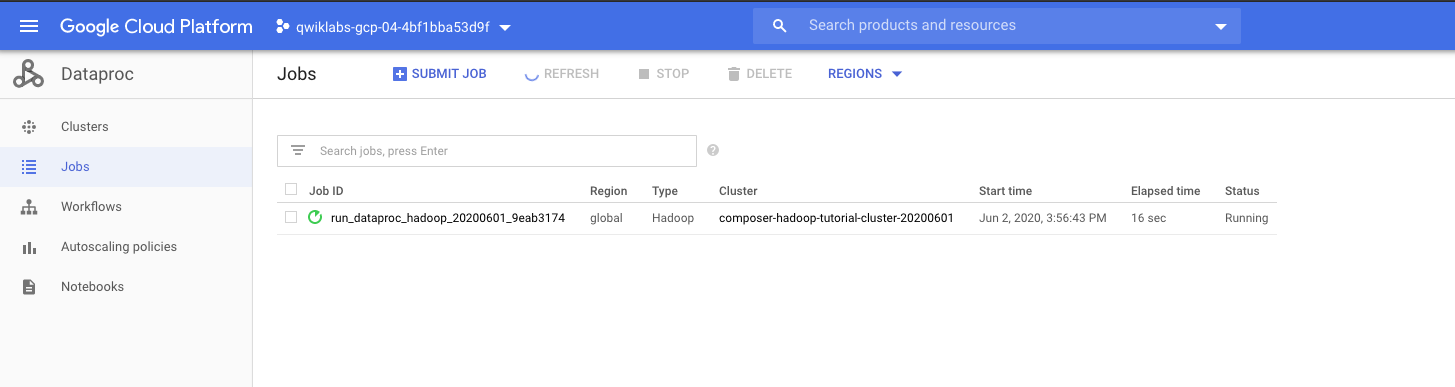
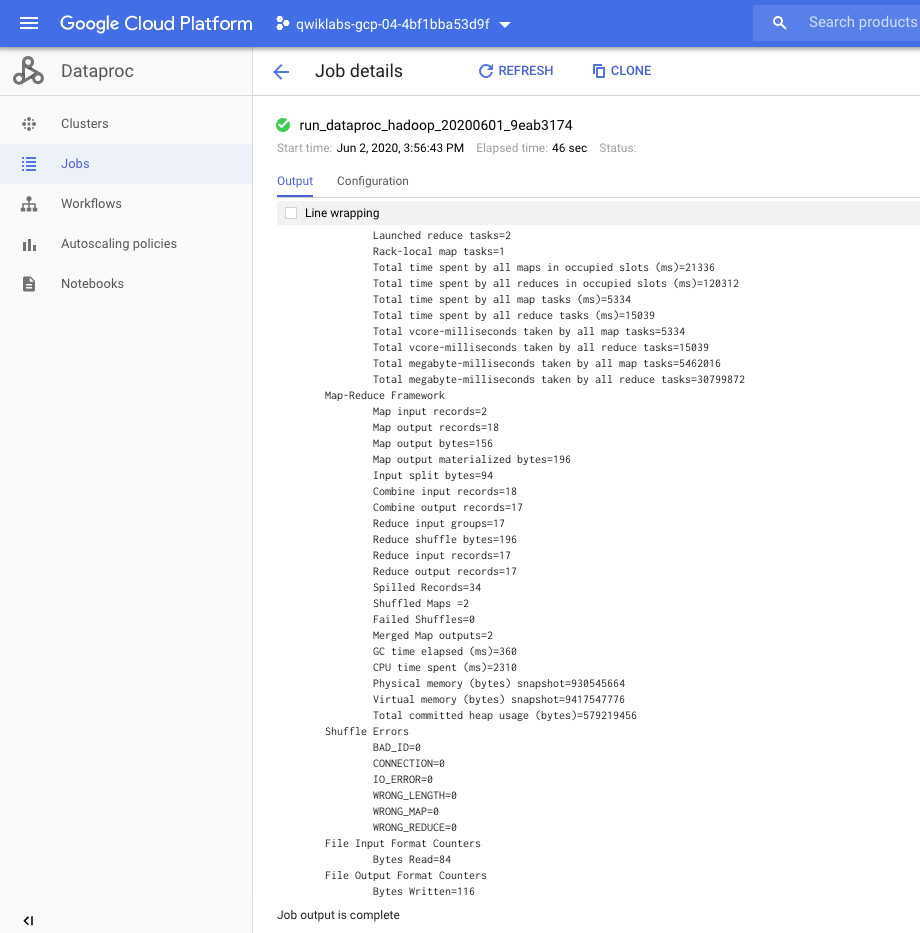
job完成后,GSC的情况