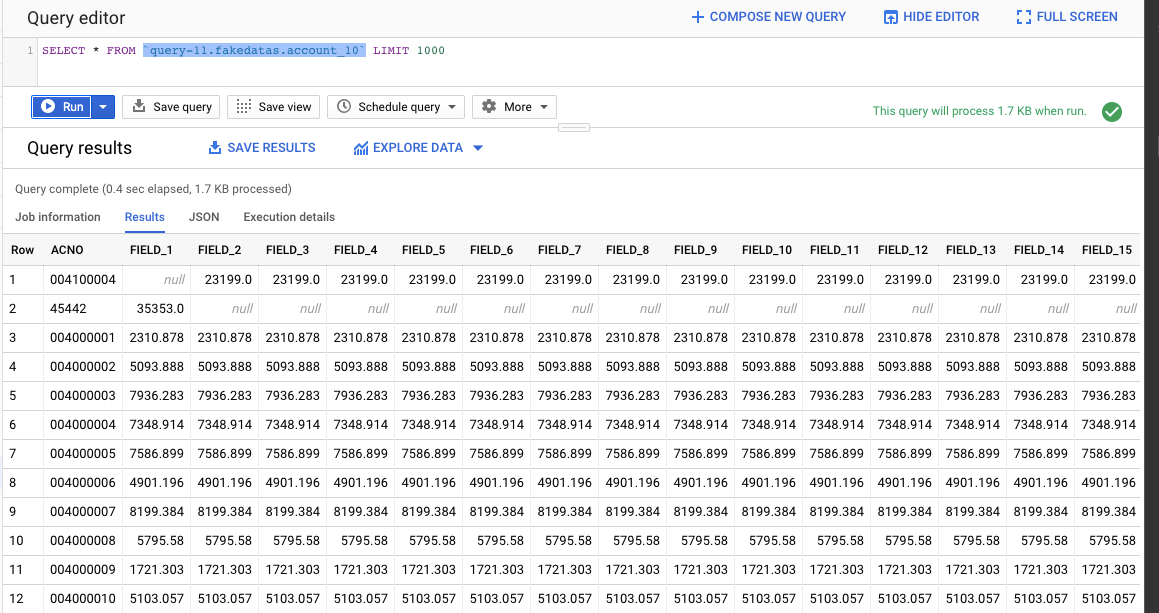
这里我主要讲得是如何通过dataflow把数据传入Bigquery
概念: streaming 就是 动态的意思, streaming data就是动态数据, job status is streaming 就是这个作业是一直持续的
大体流程是
create dataset,table in Bigquery >> create topic in SubPub
| >> create job and run >> public message in topic
| >> go to your job to check wrte SucessfulRecords
| >> go to your bigquery to check your data
具体流程是
- 首先去project 创建dataset和table
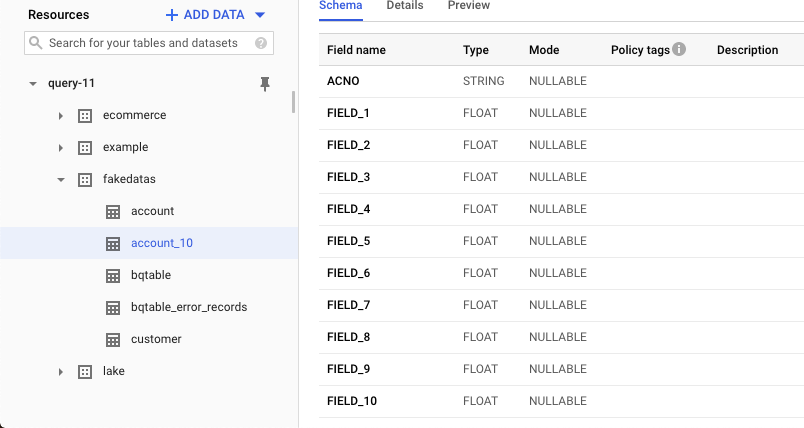
- 然后我们去到Dataflow, create job from template
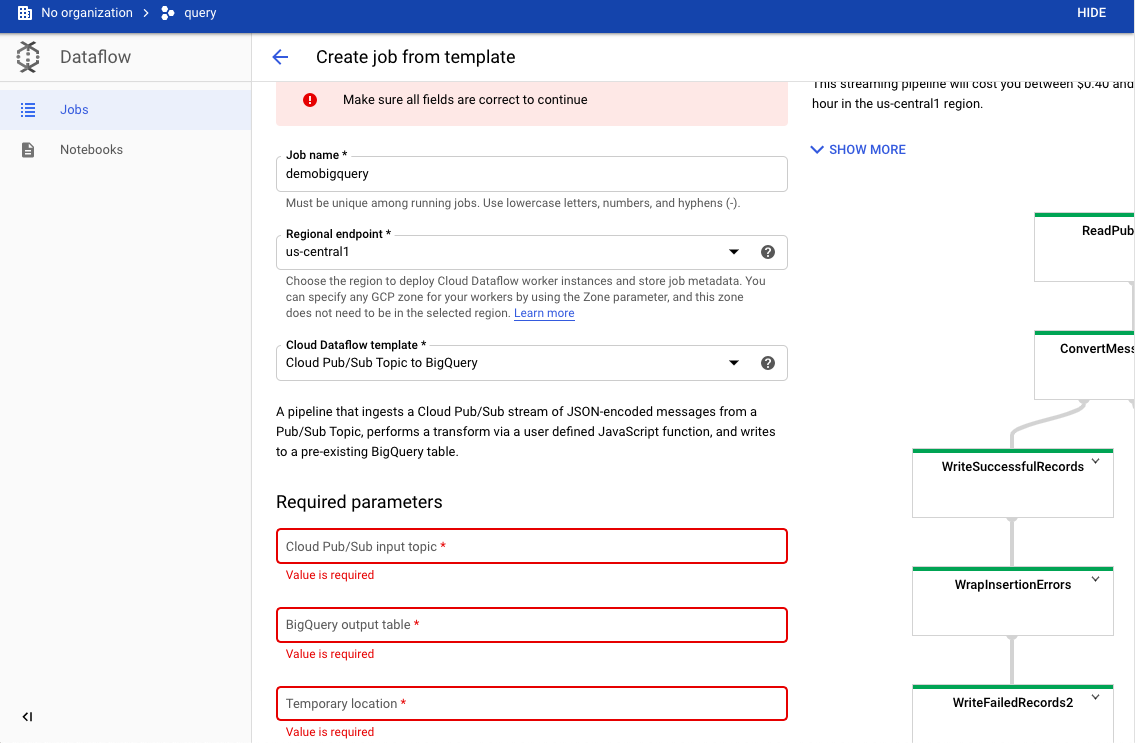
- 这里有几点我们要填:
job name: 作业名字
cloud pub/sub input topic: 输入话题,dataflow输入数据到bigquery创建一个topic
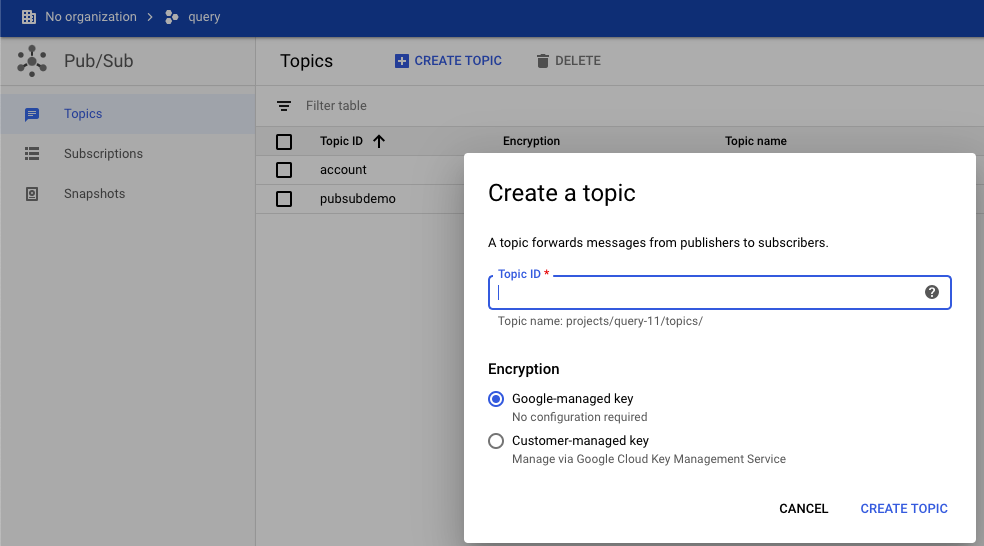
所以,我们这里去到Pub/Sub,创建topic,把topic name 放到 cloud pub/sub input topic
Bigquery output: Bigquery接收数据的table表,这里我们去到我们第一步创建的页面,复制表格整体路径
Temporary location: 这里是创建数据临时放的地方,这个文件可以放在gs://my_bucket/tmp中, 注意,这个tmp文件夹一定要存在, 这个tmp文件夹可以给多个job存放
- 然后run job
- run job成功后,我们先去到我们的topic中,然后选择PUBLISH MESSAGE,
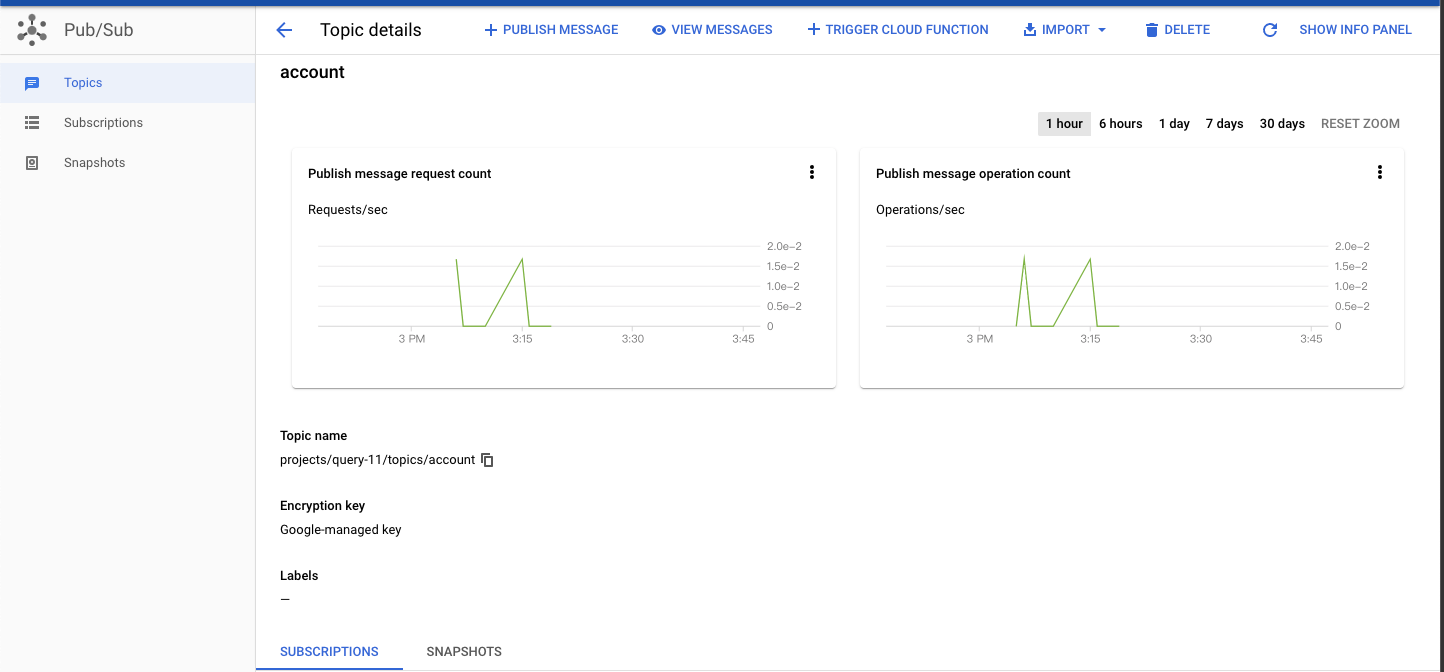
然后我们在Message body上输入我们需要输入的数据,数据格式是json格式{"key":"value","k","v"},然后publish

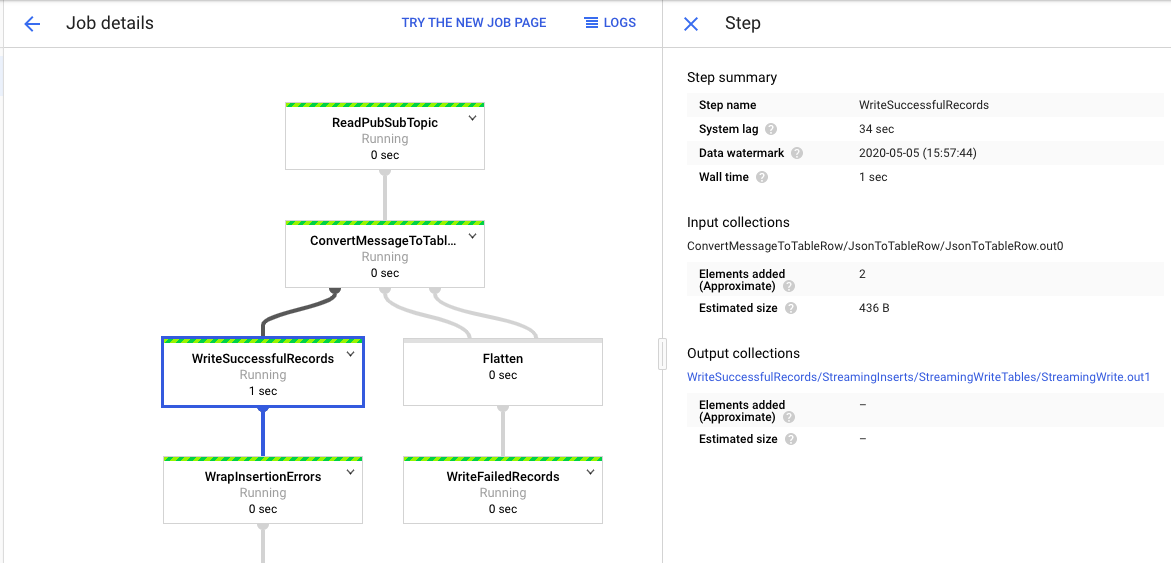
- 然后我们回到job,查看job detail, 我们点击writesuccessfulRecords,可以看到右边Elements added 出现了你添加了多少条,比如我添加了两条,他就显示2条
- 最后我们可以去bigquery查看