去到控制台,确认cloud dataproc API已启用
去dataproc->cluster->create cluster
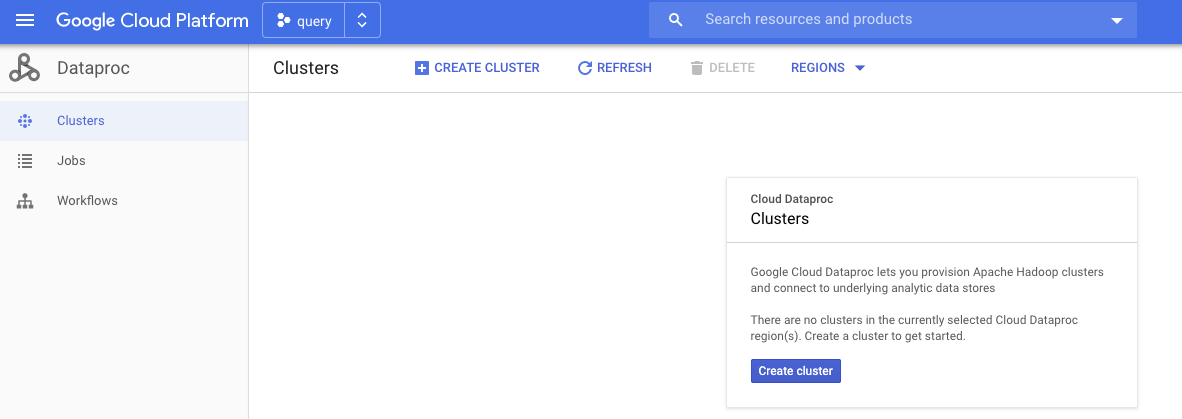
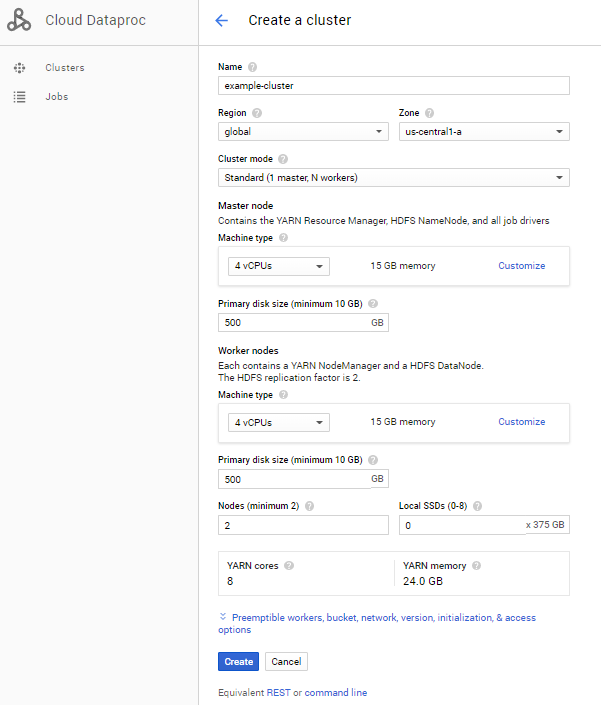
create cluster后在以下字段输入对应值

具体如下:
以上控制台的步骤,可以直接通过gcloud terminal代码实现
gcloud set config project project ID # 设置指定项目id
gcloud config set dataproc/region global #在dataproc设置region,这一步很重要
gcloud dataproc clusters create example-cluster
这样gcp就会帮你搭建cluster了
创建集群成功后,运行job
去job,选择 sumbit job
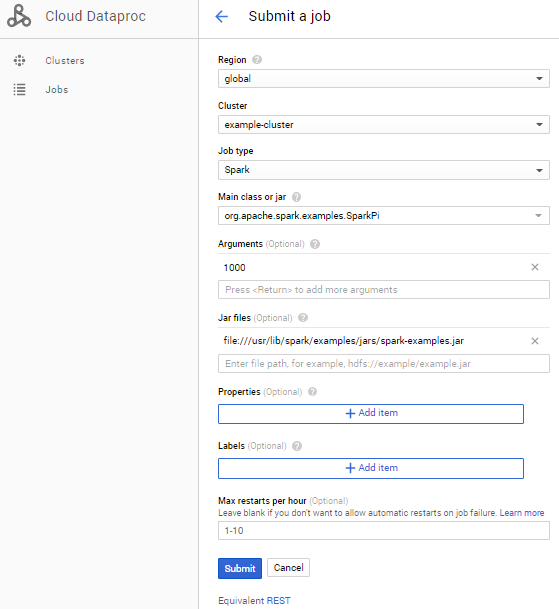
在对应字段输入对应值

具体如下,输入完成后点击sumbit
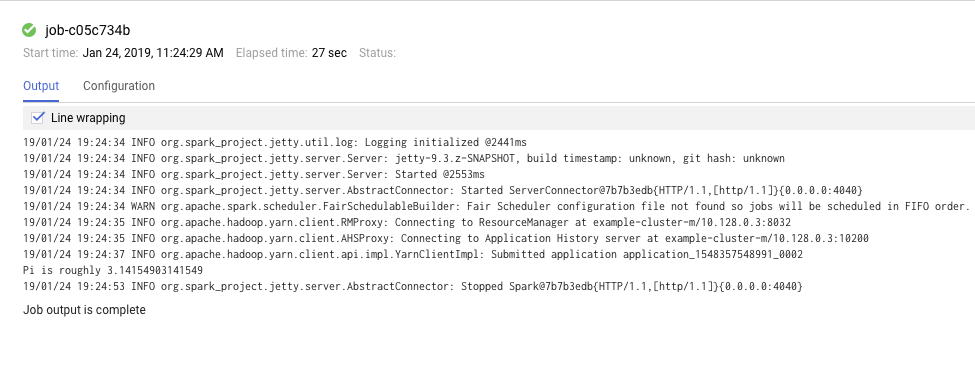
我们可以点击job id 查看结果和日志
以上步骤,我们同样可以用代码在GCPterminal上操作
gcloud dataproc jobs submit spark --cluster example-cluster \
--class org.apache.spark.examples.SparkPi \
--jars file:///usr/lib/spark/examples/jars/spark-examples.jar -- 1000
我们把job打包成jar,然后用submit spark 来运行 命令 gcloud dataproc jobs submit spark --cluster 集群名称 \ --class 类名 --jars jar包路径 --task数量
我们可以可以更新worker数量
gcloud dataproc clusters update 集群名字 -num-workers=数量
gcloud dataproc clusters update example-cluster --num-workers= 4
我们可以参考集群设置
gcloud dataproc clusters describe example-cluster
关于spark jar包和class问题
用dataproc创建集群和运行spark job 完成!!
关于spark job,stage,task的理解和参考
用gcloud来启cluster命令
在dataproc创建集群
CLUSTER_NAME=my-cluster
ZONE=us-east1-b
BUCKET_NAME=bm_reddit
REGION=us-east1
gcloud beta dataproc clusters create ${CLUSTER_NAME} \
--zone=${ZONE} \
--metadata 'PIP_PACKAGES=google-cloud-storage' \
--worker-machine-type n1-standard-1 \
--num-workers 2 \
--image-version 1.4-debian9 \
--initialization-actions gs://dataproc-initialization-actions/spark-nlp/spark-nlp.sh,gs://dataproc-initialization-actions/python/pip-install.sh \
--region=${REGION} \
--optional-components=JUPYTER,ANACONDA \
--enable-component-gateway \
--worker-boot-disk-size=30
参数说明:
metadata指源数据,比如想要安装CONDA_PACKAGE,我们
--metadata 'CONDA_PACKAGES=scipy=1.0.0 tensorflow' \
如果想安装pip_package,我们可以
--metadata 'PIP_PACKAGES=pandas==0.23.0 scipy==1.1.0' \
详细可以参考链接
Install PyPI packages
--initialization-actions gs://goog-dataproc-initialization-actions-${REGION}/python/pip-install.sh
Install Conda packages
--initialization-actions gs://goog-dataproc-initialization-actions-${REGION}/python/conda-install.sh
--initialization-actions是用在安装metadata的包
--initialization-actions \
gs://goog-dataproc-initialization-actions-${REGION}/conda/bootstrap-conda.sh,gs://goog-dataproc-initialization-actions-${REGION}/conda/install-conda-env.sh
下载代码
cd
git clone https://github.com/GoogleCloudPlatform/cloud-dataproc
cd cloud-dataproc/codelabs/spark-nlp
运行
gcloud dataproc jobs submit pyspark --cluster ${CLUSTER_NAME}\
--properties=spark.jars.packages=JohnSnowLabs:spark-nlp:2.0.8 \
--driver-log-levels root=FATAL \
topic_model.py \
-- ${BUCKET_NAME}
CLUSTER_NAME=newnew gcloud beta dataproc clusters create ${CLUSTER_NAME} \ --region=global \ --zone=us-east1-b \ --worker-machine-type n1-standard-2 \ --num-workers 2 \ --image-version 1.5-debian \ --initialization-actions gs://dataproc-initialization-actions/python/pip-install.sh \ --metadata 'PIP_PACKAGES=google-cloud-storage avro-python3 dask[dataframe] gcsfs fastavro' \ --enable-component-gateway \ --worker-boot-disk-size=40 \ --optional-components=JUPYTER,ANACONDA \ --enable-component-gateway \ --autoscaling-policy=global
workerConfig: minInstances: 2 maxInstances: 100 weight: 1 secondaryWorkerConfig: minInstances: 0 maxInstances: 100 weight: 1 basicAlgorithm: cooldownPeriod: 4m yarnConfig: scaleUpFactor: 0.05 scaleDownFactor: 1.0 scaleUpMinWorkerFraction: 0.0 scaleDownMinWorkerFraction: 0.0 gracefulDecommissionTimeout: 1h
常见错误
案例1:cpus的限额问题 Multiple validation errors: - Insufficient 'CPUS' quota. Requested 12.0, available 7.0. - Insufficient 'CPUS_ALL_REGIONS' quota. Requested 12.0, available 11.0. - This request exceeds CPU quota. Some things to try: request fewer workers (a minimum of 2 is required), use smaller master and/or worker machine types (such as n1-standard-2).
这里的insufficent 'CPUS' 只的是master和worker所有的node的cpus数量总和 Insufficient 'CPUS_ALL_REGIONS' quota是在全球的cpus限额,如果region选择global, 那么这里限额就是11(available 11), 如果region选择时某个地区,比如us-central1,那么我这里的quota就是7.为什么是7呢,因为谷歌的试用账号最多只能有8CPUs,我这个project里面已经在一个地区区域创建了一个vm,这个vm的machining type是(n1-standard-1 (1 vCPU, 3.75 GB memory)),所以占用了一个cpu,所以地方region的cpus可用额度就是8-1=7 同理,全球的话是12cpu,我已经用了1个了,所以全球剩下的就是12-1=11.
案例2: yarn core数 和 yarn memory yarn core = worker的node个数 vcpu yarn memory = worker的node个数 memoery * 0.8
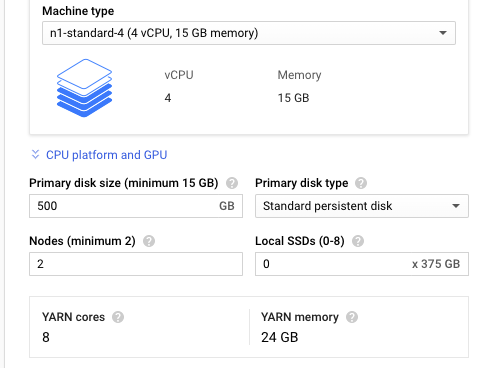
google对yarn memoery的定义: The number of worker nodes times the amount of memory on each node times the fraction given to YARN (0.8)
google对yarn coreds的定义: the number of worker nodes times the number of vCPUs per node
创建集群后,使用jupyter, 去到cluster,然后去到web interfaces,选择jupyter
如果运行spark的时候,出现 Py4JJavaError错误 可以安装
conda install -c cyclus java-jdk
如果想安装python3
!conda create -n py36 python=3.6 anaconda
Dataproc image version 1.3 或者之前的话默认是python2.7
所以我们最好安装Dataproc image version 1.4+,默认就是python3,具体详细如下
Miniconda3 is installed on Dataproc 1.4+ clusters. The default Python interpreter is Python 3.6 for Dataproc 1.4 and Python 3.7 for Dataproc 1.5, located on the VM instance at /opt/conda/miniconda3/bin/python3.6 and /opt/conda/miniconda3/bin/python3.7, respectively. Python 2.7 is also available at /usr/bin/python2.7.