一, 准备阶段
Spark的安装大多比较麻烦,而Mac安装Spark非常简单,本文分三部分内容。
- 安装JDK
- 安装Spark
- 简单测试这里具体可以参考链接
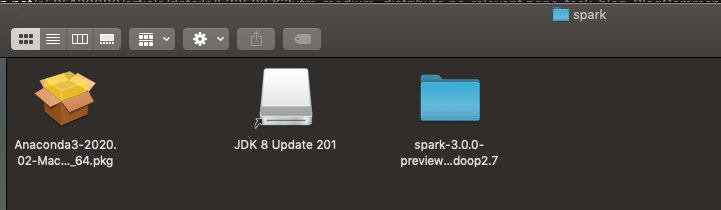
我的u盘有 JDK + annocada + spark,所以直接pass下载安装步骤啦(如图显示),双击点击JDK,Anaconda3安装就可以了,spark-3.0.0-preview2-bin-hadoop2.7就是spark,直接跳到测试阶段
打开终端,切换到spark的路径(spark-3.0.0-preview2-bin-hadoop2.7): 然后输入
./sbin/start-master.sh
然后再(http://localhost:8080),就可以看到效果:
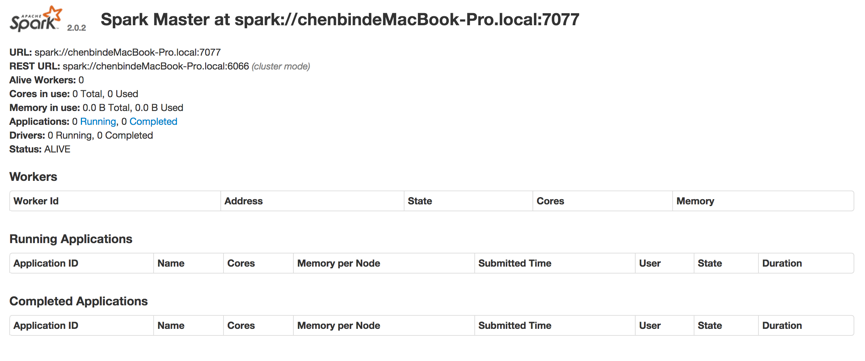
表示安装成功了
然后在一个新的终端,进入同样的spark路径,然后输入
./bin/spark-class org.apache.spark.deploy.worker.Worker spark://IP:PORT
这里的spark://IP:PORT修改成图片上的URL,如: ./bin/spark-class org.apache.spark.deploy.worker.Worker spark://chenbindeMacBook-Pro.local:7077
这样我们就开启了一个新的worker
然后我们在终端command+c就可以关掉worker
最后是关掉主机,在终端输入
./sbin/stop-master.sh
这个是简单版的
二 Anocada+jupyter+spark
我们安装好spark,jdk后,我们还要安装Anocada,我的文件里面也有,直接双击安装就可以了
1 我们切换到主目录
2 #打开bash_profile
3 设置anaconda和spark路径, 注意!!!这里spark_path路径是spark的具体路径
4 使命令立刻生效
cd ~
open .bash_profile
export PATH="/Applications/anaconda3/bin:$PATH"
export SPARK_PATH="/Users/flybird/Desktop/spark/spark-3.0.0-preview2-bin-hadoop2.7"
export PATH=$SPARK_PATH/bin:$PATH
source .bash_profile
安装pyspark,这一步很重要哦
sudo pip install pyspark -i https://pypi.douban.com/simple/
在Jupyter Notebook里运行PySpark, 配置PySpark driver
详细教程可以看这里url链接 配置PySpark driver,当运行pyspark命令就直接自动打开一个Jupyter Notebook,此时shell端不会打开,具体配置步骤:
sudo vim ~/.bashrc 在这个文件添加配置PySpark driver的环境变量
export PYSPARK_DRIVER_PYTHON=jupyter
export PYSPARK_DRIVER_PYTHON_OPTS='notebook'
source ~/.bashrc
然后重启terminal
启动jupyter notebook3
启动后,我们在jupyter notebook上创建python文件
然后输入以下命令
import os
import sys
spark_path = os.environ.get('SPARK_PATH', None)
sys.path.insert(0, os.path.join(spark_path, 'python/lib/py4j-0.10.8.1-src.zip'))
exec(open(os.path.join(spark_path, 'python/pyspark/shell.py')).read())
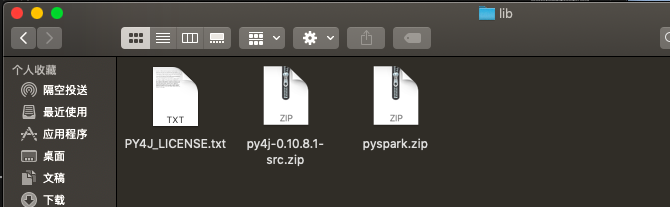
py4j-0.10.8.1-src.zip需要根据实际名称修改,如果是用我的包,就不用改,如果是用spark官网下载的,就需要对应的zip文件名字
输入命令后的效果如下, 然后输入sc,查看相应的输出:
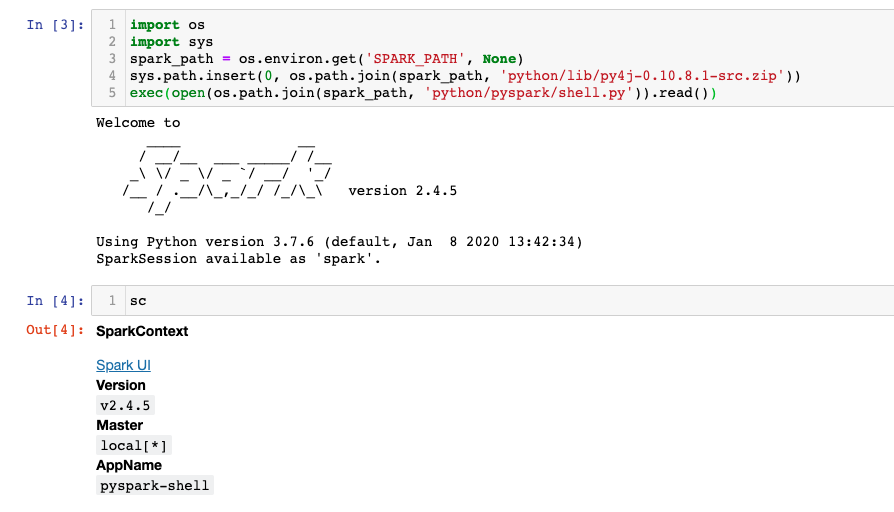
可以用command来试试一下命令
import pyspark
import random
sc = pyspark.SparkContext(appName="Pi")
num_samples = 100000000
def inside(p):
x, y = random.random(), random.random()
return x*x + y*y < 1
count = sc.parallelize(range(0, num_samples)).filter(inside).count()
pi = 4 * count / num_samples
print(pi)
sc.stop()
如果发现出现
Unsupported class file major version 57
就是jdk版本问题,去到终端
java -version #查看版本 java version "13.0.2" 2020-01-14
cd /Library/Java/JavaVirtualMachines
ls
sudo rm -rf jdk-13.0.2.jdk #删除java version
安装JDK(jdk-8u251),下载jdk-8u251-macosx-x64.dmg
然后再回到jupyter notebook,重新输入命令,查看是否成功
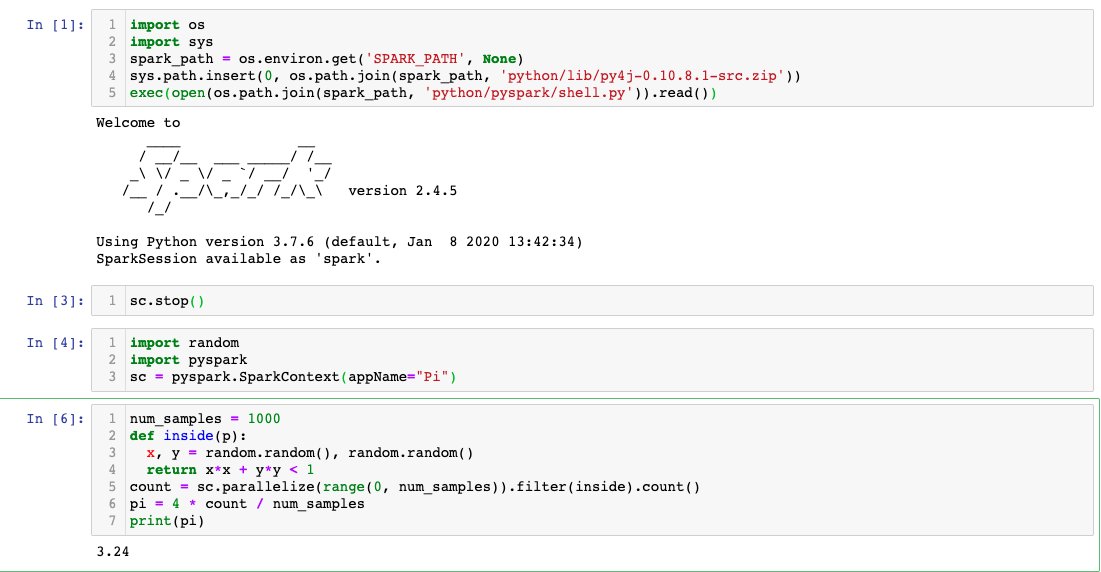
Pycharm设置啦
Pycharm这里具体可以参考一下文章 配置原因:在pyspark命令行 练习比较麻烦,不能自动补全,浪费时间。Jupyter notebook 是最理想的,但是还没配置成功。
1.打开pycharm,新建一个工程
2.点击 run --Edit Configuration..
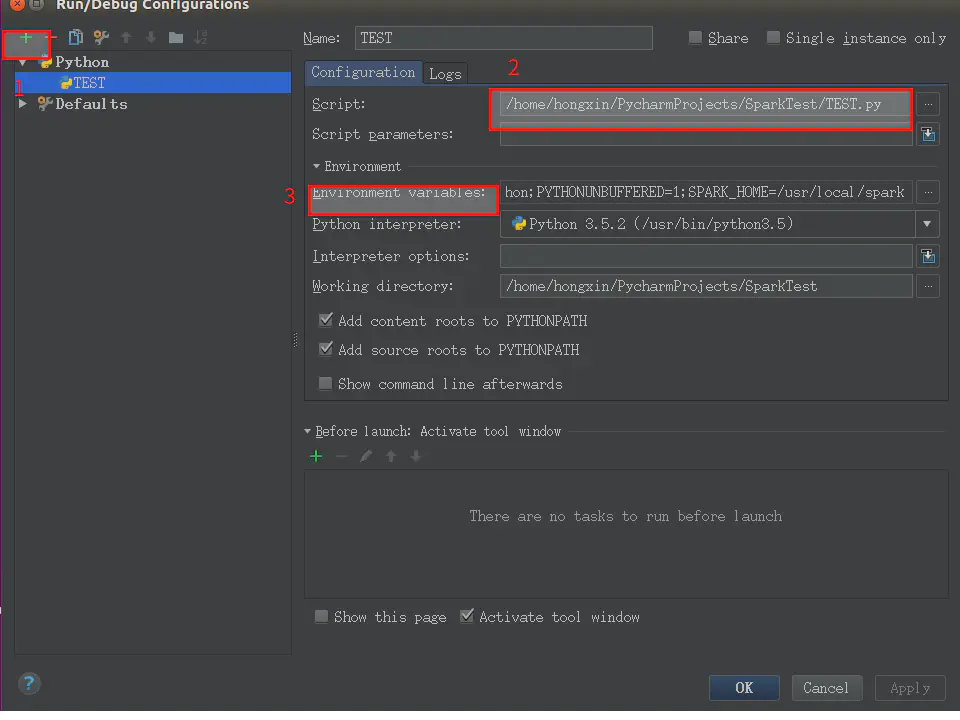
3.配置
3.1 新建 Python ,起个名
3.2 配置script,指向你要引用 spark 的那个文件
3.3 Enviroment variables:
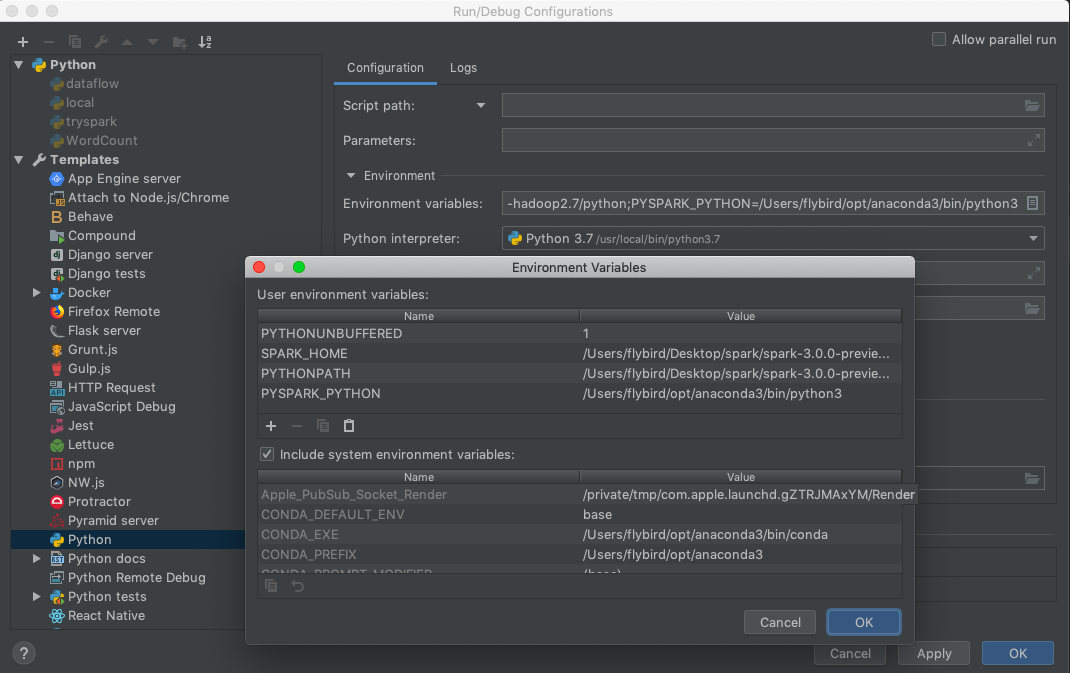 可以直接在Enviroment variables上输入:
PYTHONUNBUFFERED=1;SPARK_HOME=/Users/flybird/Desktop/spark/spark-3.0.0-preview2-bin-hadoop2.7;PYTHONPATH=/Users/flybird/Desktop/spark/spark-3.0.0-preview2-bin-hadoop2.7/python;PYSPARK_PYTHON=/Users/flybird/opt/anaconda3/bin/python3
可以直接在Enviroment variables上输入:
PYTHONUNBUFFERED=1;SPARK_HOME=/Users/flybird/Desktop/spark/spark-3.0.0-preview2-bin-hadoop2.7;PYTHONPATH=/Users/flybird/Desktop/spark/spark-3.0.0-preview2-bin-hadoop2.7/python;PYSPARK_PYTHON=/Users/flybird/opt/anaconda3/bin/python3
PYSPARK_PYTHON; 指向 你本机 的 python 路径, (可以去终端输入which python 来找到路径)
SPARK_HOME :指向 spark 安装目录(就是spark-3.0.0-preview2-bin-hadoop2.7的绝对路径)
PYTHONPATH:指向 spark 安装目录的 Python 文件夹(就是spark-3.0.0-preview2-bin-hadoop2.7的python文件夹的绝对路径)
4 安装 py4j sudo pip3 install py4j
5.看到网上很多教程,一般都只执行到第四步即可,但是我仍然无法导入 pyspark 包,还需要下面的步骤:
选择 File--->setting--->你的project--->project structure
右上角Add content root添加:py4j-some-version.zip和pyspark.zip的路径(这两个文件都在Spark中的python文件夹下)
这里我们可以去到spark中的python文件夹(spark-3.0.0-preview2-bin-hadoop2.7/python),然后查找zip!,然后看到选择添加就可以了
6 测试程序 用之前的代码再次测试,一样可以了